Extraire un tableau de données d'un document PDF
PDF n'est pas un format idéal pour transmettre des données, mais parfois on ne vous donne que ça et il faut faire avec. Heureusement, des bienfaiteurs ont créé le logiciel tabula-java. Ce logiciel est censé trouver automatiquement les données, mais il dispose d'un paramétrage pour lui indiquer où elles se trouvent. Avec les documents qu'on m'a donnés, j'ai dû utiliser la seconde méthode et ce n'est pas évident alors je le note ici pour m'en souvenir.
- J'ouvre le PDF dans Inkscape avec l'option Import Poppler/Cairo et non l'option Importation interne, parce que seul l'import Poppler/Cairo respecte la mise en page du PDF à 100 %
- Je règle l'unité par défaut du document (Maj Ctrl D) sur pt (pas sur px ou cm)
-
Je place des guides sur les limites de lignes et de colonnes : clic dans la règle du haut et glisser vers le bas, clic dans la règle de gauche et glisser vers la droite
(image d'illustration)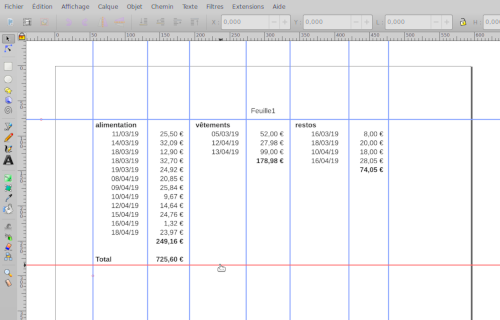
-
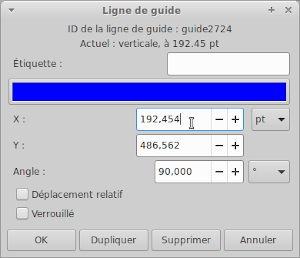
Je relève les coordonnées de la zone qui délimite le tableau (x, y), puis les coordonnées des colonnes (x seulement) en faisant un double-clic sur les guides :
-
Je peux maintenant lancer tabula. Il y a des documents qui ont des marges différentes pour les pages paires et impaires, donc dans ce cas il faut passer en paramètres les coordonnées relevées précédemment, et les numéros de page correspondants. Par exemple :
java -jar tabula-1.0.4-jar-with-dependencies.jar -format TSV --page 2,4,6,8,10,12 --area 141.6,21.3,764.1,565.2 --columns 63.9,275,324.3,423.6,522.6 bidule.pdf > pages-paires.tsv
Attention : Le paramètre --area est au format y1,x1,y2,x2 !
(et je demande du TSV parce que par défaut c'est du CSV) -
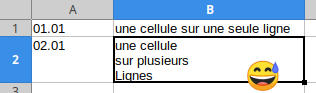
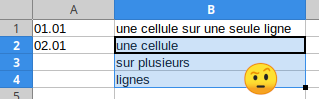
Il y a des documents PDF avec des cellules de tableau sur plusieurs lignes. Dans ce cas, tabula brise la cellule sur plusieurs lignes et le tableau contient des "fausses lignes" en trop :
-
Alors je passe la sortie de tabula dans un petit script pour recoller les cellules concernées. Ici, par exemple, ce sont les cellules de la deuxième colonne qui sont à recoller, et je repère le vrai début de ligne dans le tableau lorsque la première colonne contient une date au format JJ.MM :
<?php $current = []; function flushLigne($ligne) { echo '"'.join('"'."\t".'"', $ligne).'"'.PHP_EOL; } while ($line = fgets(STDIN)) { $line = str_replace('"', '', $line); $a = preg_split("/\t/", trim($line, "\n")); if (preg_match('/^\d{2}\.\d{2}$/', $a[0])) { flushLigne($current); $current = $a; } else { $current[1] .= "\r".$a[1]; } } flushLigne($current);Ou en deux coups de sed :sed ':a ; $!N ; s/\n\t/\r/ ; ta ; P ; D' | sed -E 's/\t([^\t]*)/\t"\1"/' -
Je peux ouvrir le résultat dans un tableur comme LibreOffice ou le mettre dans une base de données.